Армейские исследователи разработали подход к обучению с подкреплением, который позволит группам беспилотных воздушных и наземных транспортных средств оптимально выполнять различные задачи, сводя к минимуму неопределенность характеристик.
Рой — это метод операций, при котором несколько автономных систем действуют как единое целое, активно координируя свои действия.
Армейские исследователи заявили, что будущие многодоменные сражения потребуют множества динамически связанных, скоординированных разнородных мобильных платформ, чтобы превзойти возможности противника и угрозы, нацеленные на войска США.
По словам д-ра Джемина Джорджа из Лаборатории армейских исследований Командования развития боевых возможностей армии США, армия ищет технологии роения, чтобы иметь возможность выполнять трудоемкие или опасные задачи.
«Поиск оптимальной политики наведения для этих скопившихся машин в режиме реального времени является ключевым требованием для повышения тактической ситуационной осведомленности бойцов, что позволяет армии США доминировать в сложной обстановке», — сказал Джордж.
Обучение с подкреплением обеспечивает способ оптимального управления неопределенными агентами для достижения многоцелевых целей, когда точная модель агента недоступна; однако существующие схемы обучения с подкреплением могут применяться только централизованно, что требует объединения информации о состоянии всего роя в центральном учащемся. По словам Джорджа, это резко увеличивает вычислительную сложность и требования к обмену данными, что приводит к неоправданному увеличению времени обучения.
Чтобы решить эту проблему, в сотрудничестве с профессором Аранья Чакраборти из Университета штата Северная Каролина и профессором Хэ Бай из Университета штата Оклахома Джордж создал исследовательскую работу, направленную на решение крупномасштабной проблемы обучения с подкреплением, состоящей из нескольких агентов. Армия профинансировала эти усилия через награду директора за исследования за внешнюю совместную инициативу, лабораторную программу, направленную на стимулирование и поддержку новых и инновационных исследований в сотрудничестве с внешними партнерами.
Основная цель этих усилий — разработать теоретическую основу для оптимального управления на основе данных для крупномасштабных роевых сетей, в которых управляющие действия будут предприниматься на основе данных низкоразмерных измерений вместо динамических моделей.
Текущий подход называется иерархическим обучением с подкреплением, или HRL, и он разделяет цель глобального управления на несколько иерархий, а именно: микроскопический контроль на множестве малых групп и макроскопический контроль на уровне роя.
«Каждая иерархия имеет собственный цикл обучения с соответствующими локальными и глобальными функциями вознаграждения», — сказал Джордж. «Мы смогли значительно сократить время обучения, запустив эти циклы обучения параллельно».
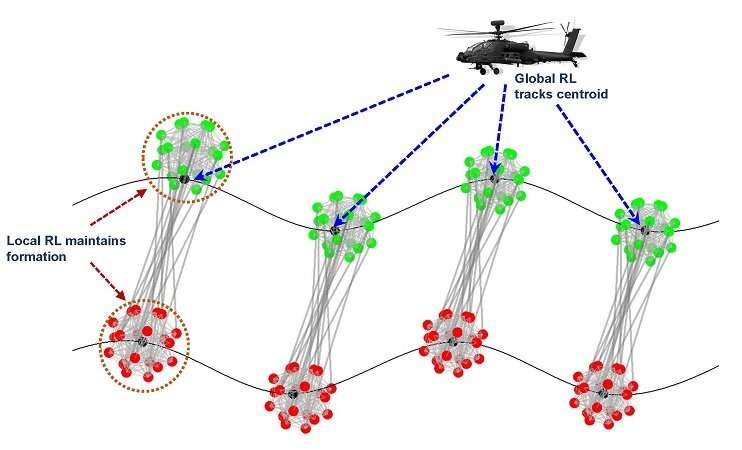
По словам Джорджа, управление роем в режиме онлайн с подкреплением сводится к решению крупномасштабного алгебраического матричного уравнения Риккати с использованием системных или роя входных-выходных данных.
Первоначальный подход исследователей к решению этого крупномасштабного матричного уравнения Риккати заключался в том, чтобы разделить рой на несколько меньших групп и параллельно реализовать обучение с локальным подкреплением на уровне группы, одновременно выполняя глобальное обучение с подкреплением на более компактном сжатом состоянии из каждой группы.
В их текущей схеме HRL используется механизм разделения, который позволяет команде иерархически аппроксимировать решение крупномасштабного матричного уравнения, сначала решая проблему локального обучения с подкреплением, а затем синтезируя глобальное управление из локальных контроллеров (путем решения задачи наименьших квадратов). запуска глобального обучения с подкреплением в агрегированном состоянии. Это еще больше сокращает время обучения.
Эксперименты показали, что по сравнению с централизованным подходом HRL удалось сократить время обучения на 80%, ограничив потерю оптимальности до 5%.
«Наши текущие усилия по HRL позволят нам разработать политику управления роями беспилотных летательных и наземных транспортных средств, чтобы они могли оптимально выполнять различные наборы миссий, даже если индивидуальная динамика роя агентов неизвестна», — сказал Джордж.
Джордж заявил, что уверен, что это исследование окажет влияние на поле битвы будущего и стало возможным благодаря новаторскому сотрудничеству, которое имело место.
«Основная цель научно-технического сообщества ARL — создавать и использовать научные знания для трансформационного превосходства», — сказал Джордж. «Привлекая внешние исследования через ECI и другие механизмы сотрудничества, мы надеемся провести подрывные фундаментальные исследования, которые приведут к модернизации армии, в то же время выступая в качестве основного связующего звена армии с мировым научным сообществом».
В настоящее время команда работает над дальнейшим улучшением своей схемы управления HRL, рассматривая оптимальное группирование агентов в рое, чтобы минимизировать вычислительную и коммуникационную сложность при одновременном ограничении разрыва в оптимальности.
Они также исследуют использование глубоких рекуррентных нейронных сетей для изучения и прогнозирования лучших шаблонов группирования и применения разработанных методов для оптимальной координации автономных воздушных и наземных транспортных средств в многодоменных операциях в густонаселенной городской местности.
Джордж вместе с партнерами ECI недавно организовал и возглавил приглашенную виртуальную сессию по мультиагентному обучению с подкреплением на Американской конференции по контролю 2020 года, где они представили результаты своих исследований.